

Schools holds a lot of data.
A municipality holds a lot of students (at the time of this writing Stockholm has 41796 registered gymnasium students, Gothenburg has 23399), and each student gets grades in 10 subjects (just to make it easier to count).
Fetching all the grades based on these two examples could potentially mean well over 100 000 grades. The size of one grade weighs about 1Kb, which would mean that the result would be 100 Mb.
That's a lot of data to download before being able to parse it. When the client make that request it needs to wait for the entire result to come back before it could handle the data, resulting in that the client times out before it can even get started.
You could see it as fetching water from a well. If you need 180 liters of water it's hard to take one big tank to the well by hand, fill it up and drag it back home.
Instead you use smaller buckets and run back and forth to the well until you've got everything you need. That's why it's better to use paginated results.
How do I paginate our SS12000 data?
Paginating our SS12000 data is very easy.
Use the query parameter limit in the request (https://api.ist.com/ss12000v2-api/source/SE00100/v2.0/grades?limit=1).
That will populate the the attribute pageToken in the response.
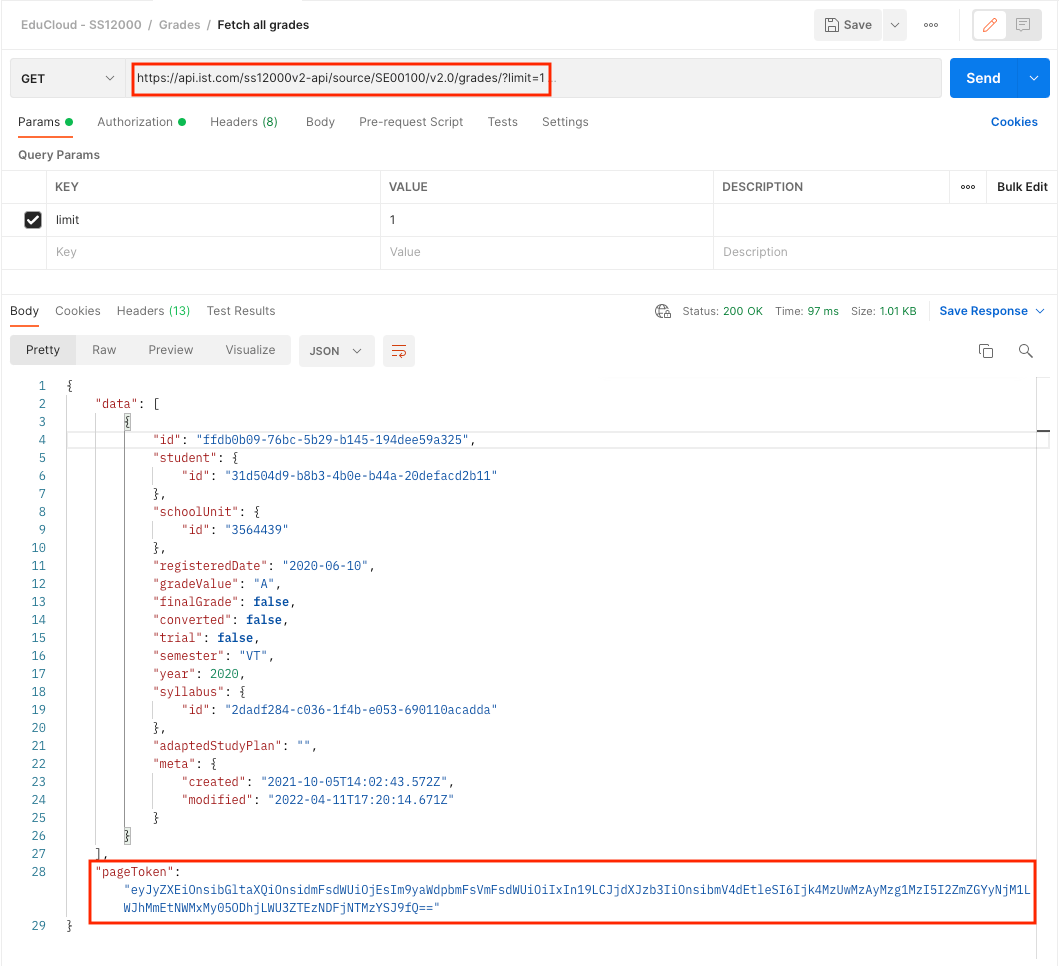
In this example I'm just using limit=1 but that is obviously just for this example.
In a real scenario a suitable page size would be between 1000 and 2000 items. It might be self-explanatory, but how many you should get in a single request all boils down to the size of the item (grades as mentioned above is 1kb per item, so 1000 grades would mean 1Mb per chunk).
Personally I would try and stick to around 1Mb.
Anyway, the next time I do my request I just use that pageToken as a parameter to get the next page of data. When you have the pageToken you don't need the limit anymore.
When you reach the last page of the book (well, rather collection) the pageToken will be empty.
That way you know you're done.
Recommended Comments
There are no comments to display.
Create an account or sign in to comment
You need to be a member in order to leave a comment
Create an account
Sign up for a new account in our community. It's easy!
Register a new accountSign in
Already have an account? Sign in here.
Sign In Now